@TOC
本文主要讲解各种优化器,对应的PyTorch实现放在下篇torch.optim
一、GD
GD(gradient descent)梯度下降,在机器学习中对模型进行更新,更新如下所示
这是最原始的剃度下降方法,每次计算梯度时都需要对整个训练集进行遍历,即需要训练集的全部数据。当我们的数据集非常大时对整个数据集进行计算是很麻烦的,而且每次更新参数
的数值时都很慢,也就是说我们需要迭代无数多次而每次都需要对整个数据集进行计算梯度,耗时很长,而且当参数移动到局部最优点(鞍点,梯度为0)时,就会陷入其中,参数停止更新
由于本文主要讲解SGD及其改进,所以对GD不做详细介绍
二、SGD及其改进
与GD不同,SGD每次从数据集中取出部分mini-batch,求部分数据集的loss,即用部分数据的梯度来近似整体的梯度,首先和GD一样,我们需要了解梯度更新的过程
其中
:学习率
:在t时刻的参数值
:在
时刻的梯度
计算与更新过程如图所示
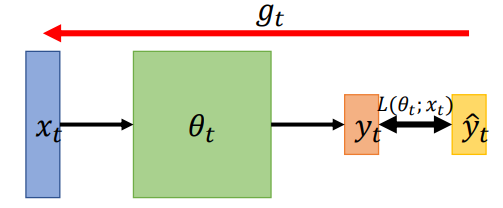
1. SGD
SGD与GD不同的地方就在于SGD使用的是mini batch,如下图所示,SGD一共分为如下几步
- 计算
处的梯度:首先我们在位置
处,计算
,注意红色的箭头代表梯度的方法,我们的目的是减小
,而梯度的方向是函数增加的方向,所以下一步更新
- 更新
- 计算在
处的梯度并重复上述过程,直到
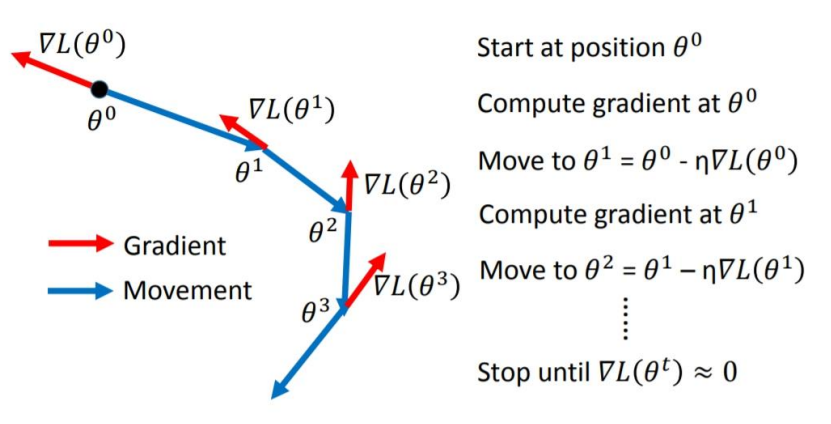
2. SGDM
SGDM是上述SGD的改进加入了动量,假设在SGD的优化过程中梯度,此时参数
的值不会继续改变,如下图所示,但是当我们加入momentum以后,即使梯度为0,动量也会告诉参数要继续变化
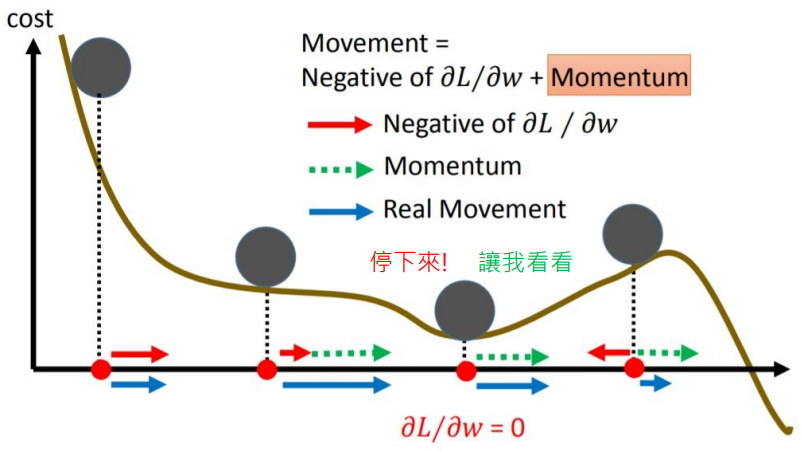
那究竟什么是动量呢,这个动量和物理上的动量相似,想象一个场景我们在滑滑梯,当我们在滑梯上准备下滑时,滑梯是有一个斜度,我们在上面就有一个沿着滑梯下滑的力(也就是梯度),我们开始下滑,当我们到滑梯中间的某一处时,由于有梯度+在上一秒我们的初速度,我们不会停下,即使我们到了滑梯底部滑梯变平了我们失去了向前的力(梯度),我们依然具有之前积累的速度,所以我们会继续向前运动,SGDM就是应用了这个道理
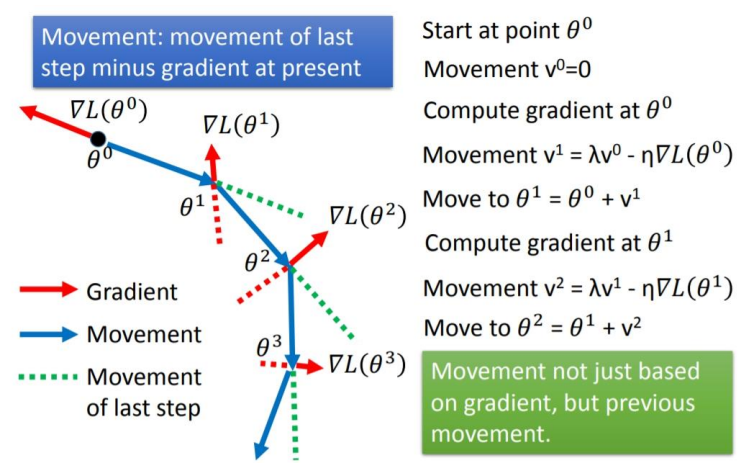
接下来看一下SGDM的具体执行过程
第一次更新------------------>
- 计算
,这个参数就是我们的动量,记录上一步梯度的反方向,也就是上一步移动的方向,由于参数是第一次变化,没有之前的记录,所以一开始
- 计算需要移动的距离:
- 更新
第二次更新------------------>
- 计算
- 计算需要移动的距离:
- 更新
重复上述过程---------------->
通过上述计算可以发现,每次移动的距离不仅取决于所在点的梯度,还取决于上一步的移动,而上一步的移动与之前所有计算过的梯度都有关
- …
3. Adagrad
与SGD不同的地方是,Adagrad在学习率上作了文章,如下公式所示
这样做的意义是什么呢?有两点
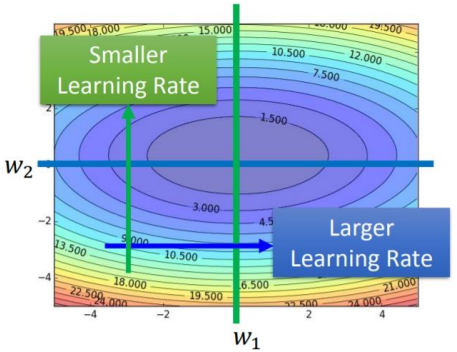
- 假设一开始梯度较大:此时学习率的分母会变大,整体的学习率减小,这样梯度下降的速度就会变慢,这是为了避免错过最低点。相当于下滑梯时如果滑梯很陡,那就慢慢滑,避免滑到最下面的时候速度过快停不下来(错过最低点)
- 假设一开始梯度较小:此时学习率的分母会变小,整体的学习率减大,这样梯度下降的速度就会变快,这是为了快速进行梯度下降。相当于下滑梯时如果滑梯很缓,那就快速滑,以尽快达到最低点,而且当剃度下降到最低点时已经进行了很多次优化,分母经过累加已经变大,学习率也会降低,剃度下降也比较平缓,不会错过最低点
4. RMSProp
上述Adagrad有一个缺点,当一开始梯度较大时学习率会变得很小,我们希望在最优解的地方梯度下降变慢,但现在我们适得其反,在一开始的时候参数更新的就非常慢,而且学习率的分母是累加的梯度,导致学习率会越来越低,为了改变这个缺点,出现了RMSProp
虽然与之前的梯度也有关,但是
的存在使得分母不会像Adagrad那样累加,让我们看一下
的变化情况
- …
5. Adam
到这里我们梳理一下,我们现在讲了GD,SGD,SGDM,Adagrad以及RMSProp
- 其中SGD是GD的改进,SGDM是SGD的改进,所以前三个算法中最优的是SGDM
- RMSProp是Adagrad的改进,所以后两个算法最优的是RMSProp
SGDM是对加入了动量,是对梯度进行了变化;RMSProp是对学习率进行了改进,而Adam结合了两者的优点,可以理解为:Adam = SGDM+RMSProp