1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
| '''
torch.optim.SGD
'''
import os
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
def create_linear_data(nums_data, if_plot=False):
"""
Create data for linear model
Args:
nums_data: how many data points that wanted
Returns:
x with shape (nums_data, 1)
"""
x = torch.linspace(2, 10, nums_data)
x = torch.unsqueeze(x,dim=1)
k = 2
y = k * x + torch.rand(x.size())
if if_plot:
plt.scatter(x.numpy(),y.numpy(),c=x.numpy())
plt.show()
datax = x
datay = y
return datax, datay
datax, datay = create_linear_data(10, if_plot=False)
length = len(datax)
class LinearDataset(Dataset):
def __init__(self, length, datax, datay):
self.len = length
self.datax = datax
self.datay = datay
def __getitem__(self, index):
datax = self.datax[index]
datay = self.datay[index]
return {'x': datax, 'y': datay}
def __len__(self):
return self.len
batch_size = 3
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
linear_loader = DataLoader(dataset=LinearDataset(length, datax, datay),
batch_size=batch_size, shuffle=True)
class Model(torch.nn.Module):
"""
Linear Regressoin Module, the input features and output
features are defaults both 1
"""
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, input):
output = self.linear(input)
print("In Model: #############################################")
print("input: ", input.size(), "output: ", output.size())
return output
model = Model()
model.cuda()
loss = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
Linear_loss = []
for i in range(10):
for data in linear_loader:
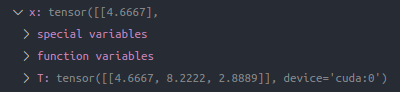
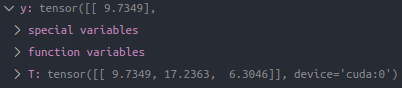
x, y = data['x'], data['y']
x = x.cuda()
y = y.cuda()
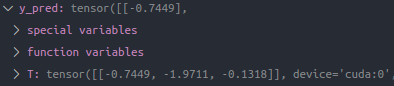
y_pred = model(x)
lloss = loss(y_pred, y)
optimizer.zero_grad()
lloss.backward()
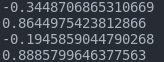
for param in model.parameters():
print(param.item())
optimizer.step()
for param in model.parameters():
print(param.item())
Linear_loss.append(lloss.item())
print("Out--->input size:", x.size(), "output_size:", y_pred.size())
loss_len = len(Linear_loss)
axis_x = range(loss_len)
plt.plot(axis_x, Linear_loss)
plt.show()
|
的一元线性回归,并且只验证