from tensorboardX import SummaryWriter #SummaryWriter encapsulates everything writer = SummaryWriter('runs/exp-1') #creates writer object. The log will be saved in 'runs/exp-1' writer2 = SummaryWriter() #creates writer2 object with auto generated file name, the dir will be something like 'runs/Aug20-17-20-33' writer3 = SummaryWriter(comment='3x learning rate') #creates writer3 object with auto generated file name, the comment will be appended to the filename. The dir will be something like 'runs/Aug20-17-20-33-3xlearning rate'
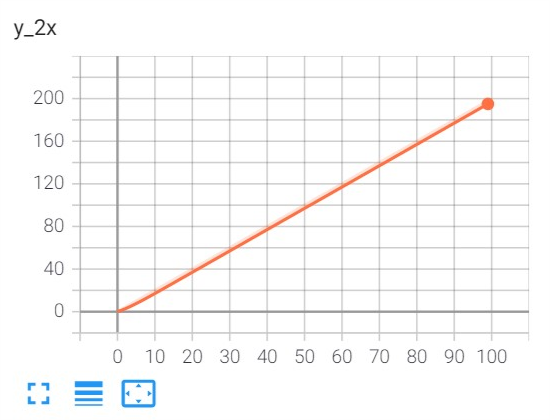
from tensorboardX import SummaryWriter import time writer = SummaryWriter("runs/scalar") x = range(100) for i in x: time.sleep(0.1) writer.add_scalar('y=2x', i * 2, i, walltime=time.time()) writer.close()
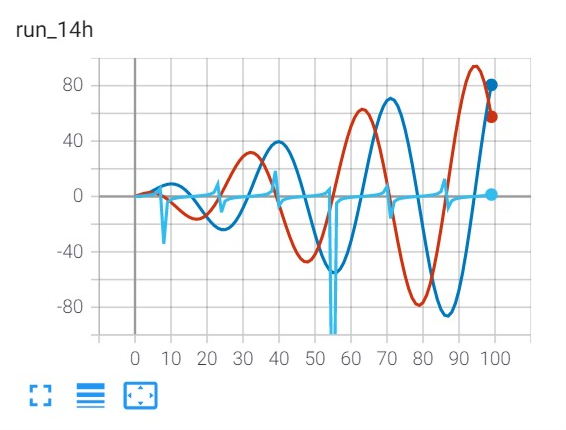
from tensorboardX import import numpy as np SummaryWriter writer = SummaryWriter() r = 5 for i inrange(100): writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r), 'xcosx':i*np.cos(i/r), 'tanx': np.tan(i/r)}, i) writer.close() # This call adds three values to the same scalar plot with the tag # 'run_14h' in TensorBoard's scalar section.
2. 记录文本
add_text(tag, text_string, global_step, walltime)
tag:数据标签
text_string:数据的值
global_step:全局步数,即x轴的值
walltime:记录event的时间,可选
1 2 3 4 5 6 7 8 9 10
from tensorboardX import SummaryWriter import time
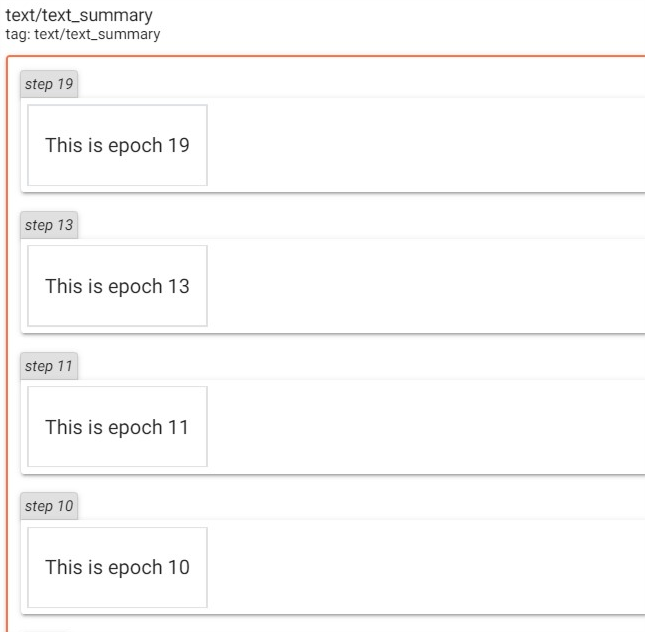
writer = SummaryWriter("runs/text") x = range(20) for i in x: # 最多添加十个epoch writer.add_text('text', "This is epoch {}".format(i), i) time.sleep(0.1) writer.close()
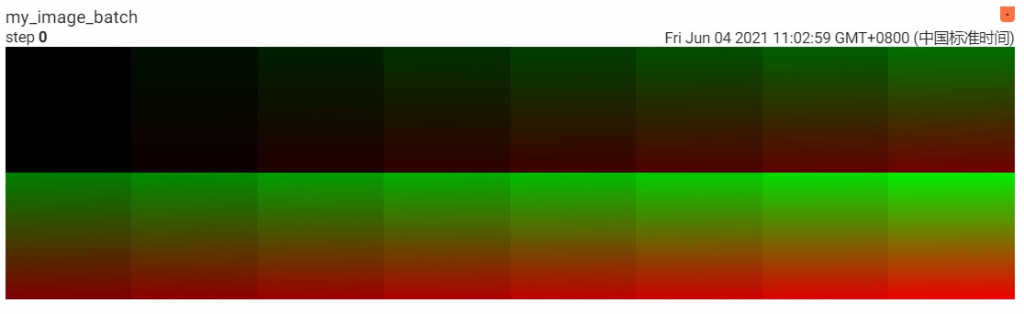
img_tensor:An uint8 or float Tensor of shape [channel, height, width] where channel is 1, 3, or 4. The elements in img_tensor can either have values in [0, 1] (float32) or [0, 255] (uint8). Users are responsible to scale the data in the correct range/type.
img_tensor: Default is (3,H,W)(3,H,W). You can use torchvision.utils.make_grid() to convert a batch of tensor into 3xHxW format or use add_images() and let us do the job. Tensor with (1,H,W)(1,H,W), (H,W)(H,W), (H,W,3)(H,W,3) is also suitible as long as corresponding dataformats argument is passed. e.g. CHW, HWC, HW.
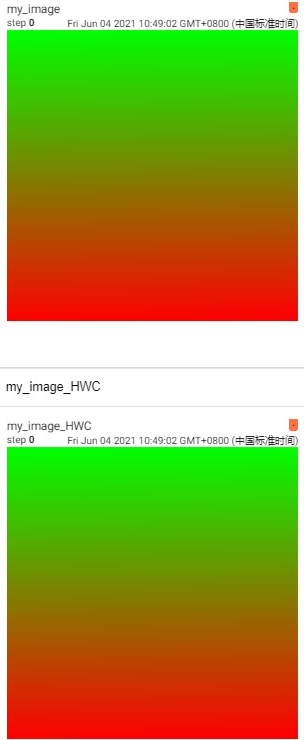
# If you have non-default dimension setting, set the dataformats argument. writer.add_image('my_image_HWC', img_HWC, 0, dataformats='HWC') writer.close()
img_tensor:An uint8 or float Tensor of shape [channel, height, width] where channel is 1, 3, or 4. The elements in img_tensor can either have values in [0, 1] (float32) or [0, 255] (uint8). Users are responsible to scale the data in the correct range/type.
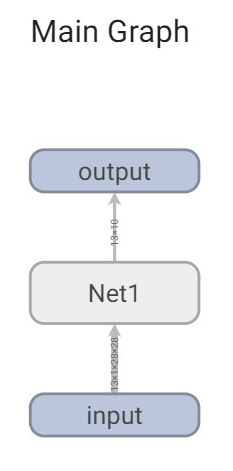
defforward(self, x): x = F.max_pool2d(self.conv1(x), 2) x = F.relu(x) + F.relu(-x) x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) x = self.bn(x) x = x.view(-1, 320) x = F.relu(self.fc1(x)) x = F.dropout(x, training=self.training) x = self.fc2(x) x = F.softmax(x, dim=1) return x
dummy_input = torch.rand(13, 1, 28, 28)
model = Net1() # 使用with语句,可以不调用w.close # with SummaryWriter(comment='Net1') as w: with SummaryWriter("runs/graph") as w: # 第一个参数为需要保存的模型 # 第二个参数为输入值->元祖类型 w.add_graph(model, (dummy_input), verbose=True)
import torch import torchvision.utils as vutils import numpy as np import torchvision.models as models from torchvision import datasets from tensorboardX import SummaryWriter