@TOC
1. DistributedSampler
torch.utils.data.distributed.DistributedSampler(dataset, num_replicas=None, rank=None, shuffle=True, seed=0, drop_last=False)
- dataset: Dataset used for sampling
- num_relicas: 参与分配的进程数,默认自己检索
- rank: 进程编号,默认自己检索
- shuffle:default=True
- seed:如果shuffle=True,对于分布式中所有处理相同,default seed=0
- drop_last:当数据除GPU无法取整的时候,是否将多余数据舍去,不舍去的话需要从头取数据补全,default=False,即不舍弃
设置dataset的子集用于分布式训练
Sampler that restricts data loading to a subset of the dataset.
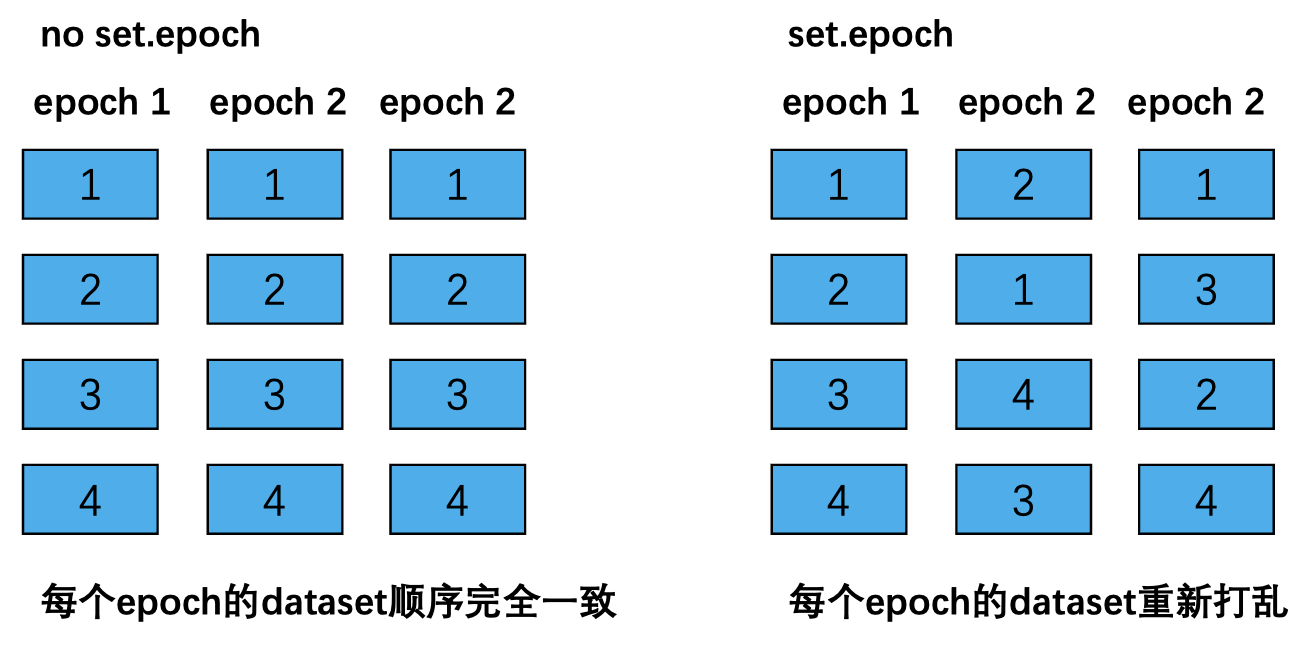
注意在分布式的模式中,在每个epoch要调用set.epoch函数,不然进行迭代时每次都是相同的数据集顺序
这个函数看着介绍比较难懂,下面通过例子来解释:
不调用set.epoch
运行:CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --master_port 29501 exe.py
1 | import torch |
调用set.epoch,即将上述代码中的sampler.set_epoch(epoch)注释取消掉
1 | ''' |
对于上述输出,当不使用set.epoch时,两个epoch的cuda:0中的数据顺序是一致的,而使用set.epoch时,两个epoch的cuda:0中的数据不同,也就是说,set.epoch在每个epoch设置了不同的随机种子
我这里采用了两张卡,最终数据是平均分配的,也就是说数据被随机的分成了两份进行分配
还有一点需要注意的:如果我们在训练过程中加入了torch.utils.data.BatchSampler,原理依旧是不变的
2. BatchSampler
torch.utils.data.BatchSampler(sampler, batch_size, drop_last)
- sampler: 一个可以迭代对象
- batch_size: mini-batch的大小
- drop_last: True的话凑不够batch_size的那部分会被舍弃
产生一个mini-batch的索引
1 | from torch.utils.data import BatchSampler |
一般来说在分布式训练的时候,先执行DistributedSampler,然后执行BatchSampler,将BatchSampler传入到DataLoader即可