distributed
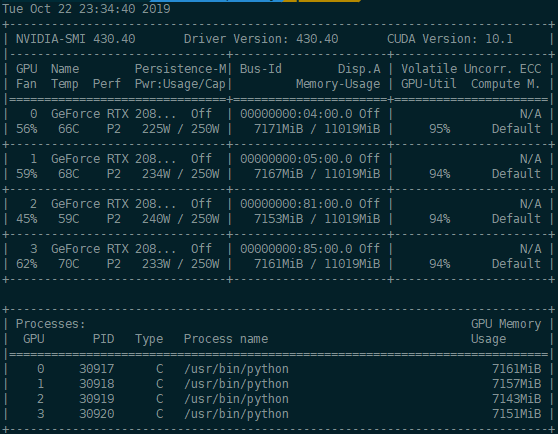
有一个坑是使用分布式计算的时候,每张卡的内存分配都应该是均匀的,但是有时候会出现0卡占用更多内存的情况,这个坑在知乎上有讨论:链接
分布式本身的内存分配应该是均匀的(左图),但是有时候会出现另一种情况(有图)
 |
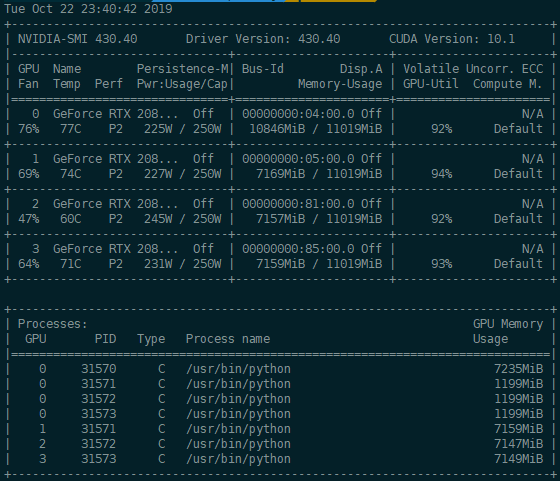 |
这是load模型的时候导致的,当用下面句子load模型时,torch.load会默认把load进来的数据放到0卡上,这样四个进程全部会在0卡占用一部分显存
1 | checkpoint = torch.load("checkpoint.pth") |
解决方法就是将load进来的数据map到cpu上
1 | checkpoint = torch.load("checkpoint.pth", map_location=torch.device('cpu')) |
计算图
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. You can enable unused parameter detection by (1) passing the keyword argument
find_unused_parameters=Truetotorch.nn.parallel.DistributedDataParallel; (2) making sure allforwardfunction outputs participate in calculating loss. If you already have done the above two steps, then the distributed data parallel module wasn’t able to locate the output tensors in the return value of your module’sforwardfunction. Please include the loss function and the structure of the return value offorwardof your module when reporting this issue (e.g. list, dict, iterable).
这里解释两个可能的原因:
- 模型中forward函数内有的参数没有参与计算,举个例子在输出图片时你输出了目标图和一个其他的参数(假设这是一个观察变量,你仅仅想看看那个参数的变化情况,而不是将他也参与反向传播),计算时只用了目标图计算loss和反向传播,此时就会报错
- 模型中的某一个操作,例如conv在forward是未使用
1 | class model(nn.Module): |
如果你的观察变量不会影响结果,即y2,你就可以将分布式中的torch.nn.parallel.DistributedDataParallel的参数find_unused_parameters=True,就不会报错了;如果会影响结果说明forward函数写错了,查看错误即可