pytorch官方提供了几种调整学习率的方法,其中优化器在torch.optim库中,调整学习率在torch.optim.lr_scheduler中,这一部分首先介绍手动进行学习率的调整,下一篇我们介绍lr_scheduler方法
在设计好网络之后我们先将网络参数放到优化器中,这些参数保存在优化器的param_group中,随后通过优化器的一些设置,例如学习率等来对其进行优化
下面通过一个例子进行介绍
首先我们构建一个简单的线性网络,如下所示,他一共包含两步操作,linear1以及linear2
1 2 3 4 5 6 7 8 9 10 class linear (nn.Module): def __init__ (self ): super (linear, self).__init__() self.linear1 = nn.Linear(2 , 3 ) self.linear2 = nn.Linear(3 , 4 ) def forward (self, x ): x = self.linear1(x) y = self.linear2(x) return y
随后我们设计一个调整学习率的函数,如下所示
1 2 3 4 def adjust_learning_rate (optimizer, epoch, lr ): lr *= (0.1 ** (epoch // 2 )) for param_group in optimizer.param_groups: param_group['lr' ] = lr
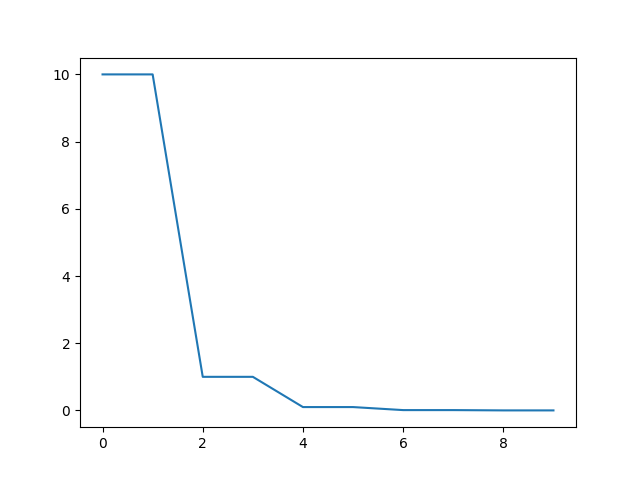
最后我们将其余流程写下来,我们采用SGD优化器,将net的所有参数传递给params参数,也就是说优化的时候网络的所有参数均参与优化。下面打印出了学习率变化以及最终曲线
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 net = linear() optimizer = optim.SGD(params=net.parameters(), lr=10 ) plt.figure() x = list (range (10 )) y = [] lr_init = optimizer.param_groups[0 ]['lr' ] for epoch in range (10 ): adjust_learning_rate(optimizer, epoch, lr_init) lr = optimizer.param_groups[0 ]['lr' ] print (epoch, lr) y.append(lr) plt.plot(x,y) plt.show() ''' 0 10.0 1 10.0 2 1.0 3 1.0 4 0.10000000000000002 5 0.10000000000000002 6 0.010000000000000002 7 0.010000000000000002 8 0.0010000000000000002 9 0.0010000000000000002 '''
如何对网络不同部分设置不同学习率?
在优化网络的时候我们会面临这样一个问题,如果我们的backbone是经过imagenet预训练的,应用的下游任务部分是我们自己设计的,我们可能需要对这两部分设置不同的学习率,比如设置backbone的学习率是自己网络的
这种修改方法很简单,optimizer的核心就是params参数,因此我们只需要将网络的参数分别包装在params即可,依然以上述linear网络为例,我们将linear1的学习率设置为linear2的两倍、
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 import torch.nn as nnimport matplotlib.pyplot as pltimport torch.optim as optimdef adjust_learning_rate (optimizer, epoch, lr1, lr2 ): """Sets the learning rate to the initial LR decayed by 10 every 2 epochs""" lr1 *= (0.1 ** (epoch // 2 )) lr2 *= (0.1 ** (epoch // 2 )) for i, param_group in enumerate (optimizer.param_groups): param_group['lr' ] = eval ("lr{}" .format (i+1 )) class linear (nn.Module): def __init__ (self ): super (linear, self).__init__() self.linear1 = nn.Linear(2 , 3 ) self.linear2 = nn.Linear(3 , 4 ) def forward (self, x ): x = self.linear1(x) y = self.linear2(x) return y net = linear() params = [{"params" : net.linear1.parameters(), "lr" :10 }, {"params" : net.linear2.parameters(), "lr" :5 }] optimizer = optim.SGD(params=params, lr=10 ) x = list (range (10 )) y1 = [] y2 = [] lr_1 = optimizer.param_groups[0 ]['lr' ] lr_2 = optimizer.param_groups[1 ]['lr' ] for epoch in range (10 ): adjust_learning_rate(optimizer, epoch, lr_1, lr_2) lr_1_ad = optimizer.param_groups[0 ]['lr' ] lr_2_ad = optimizer.param_groups[1 ]['lr' ] print ("linear1:" , epoch, lr_1_ad) print ("linear2:" , epoch, lr_2_ad) y1.append(lr_1_ad) y2.append(lr_2_ad) plt.plot(x,y1) plt.plot(x,y2) plt.legend(['linear1' , 'linear2' ], loc='upper left' ) plt.show() ''' linear1: 0 10.0 linear2: 0 5.0 linear1: 1 10.0 linear2: 1 5.0 linear1: 2 1.0 linear2: 2 0.5 linear1: 3 1.0 linear2: 3 0.5 linear1: 4 0.10000000000000002 linear2: 4 0.05000000000000001 linear1: 5 0.10000000000000002 linear2: 5 0.05000000000000001 linear1: 6 0.010000000000000002 linear2: 6 0.005000000000000001 linear1: 7 0.010000000000000002 linear2: 7 0.005000000000000001 linear1: 8 0.0010000000000000002 linear2: 8 0.0005000000000000001 linear1: 9 0.0010000000000000002 linear2: 9 0.0005000000000000001 '''
注意到上面程序的params变为了下面形式,也就是说分开传参,分开调整学习率即可
1 2 params = [{"params" : net.linear1.parameters(), "lr" :10 }, {"params" : net.linear2.parameters(), "lr" :5 }]