1. MiniGPT-4论文解析
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. KAUST
1.1 论文动机
针对GPT-4表现出来的强大的生成能力和多模态理解能力,作者提出了MiniGPT-4,模型结构很简单:一个冻住的视觉编码器,一个冻住的大语言模型Vicuna以及一个投影层。实验过程中作者发现仅仅利用原始的image-text pair进行预训练的模型包括重复以及碎片的句子,为了解决这个问题,作者收集了high-quality,well-designed数据集进一步微调模型。
训练后的模型能够根据图片创作故事和古诗的能力,能够生成图片的描述,教用户如何烹饪等等。
1.2 论文介绍
目前以GPT-4为主的大语言模型已经涌现出了很强理解能力,这种涌现的能力在小模型当中没办法体现,为了验证这种涌现能力是否能够被应用到多模态模型中,作者提出了MiniGPT-4。
MiniGPT-4的语言模型采用的是Vicuna;视觉模型采用的与BLIP-2相同,一个ViT-G/14和一个Q-Former;最后使用一层投影层来将视觉特征映射到语言模型的word embedding空间当中(相当于一个空间对齐的过程)。在训练过程中作者发现只进行预训练会导致输出重复的句子和碎片的句子,因此作者收集了额外的3500个高质量的image-text pair进行微调。
能力:模型能够生成复杂的图像描述,根据手写指令生成网站,解释不寻常的视觉现象,根据图片生成食谱,创造歌曲,生成产品广告,为图片中的问题提供解决方案等等
主要贡献
- 将视觉特征对齐到语言空间,可以实现visual-language模型的涌现能力
- 使用预训练的视觉和语言模型,MiniGPT-4可以实现更高的计算效率,并且仅训练一层投影层可以有效地将视觉特征和语言特征进行对齐
- 仅用原始的image-text pair训练模型产生的效果不佳,因此加入了额外的high-quality well-aligned image-text pair进行微调
1.3 方法细节
网络结构图如下所示
1. 网络结构
网络结构包含三个部分:一个冻住的视觉编码器,一个冻住的大语言模型Vicuna以及一个投影层。其中视觉编码器采用的是ViT-G/14,语言模型采用的是Vicuna,投影层采用的是一个线性层。
训练分为两部分:预训练使用image-text pairs来对vision-language模型进行对齐;微调使用high-quality image-text pairs来增强模型的可靠性
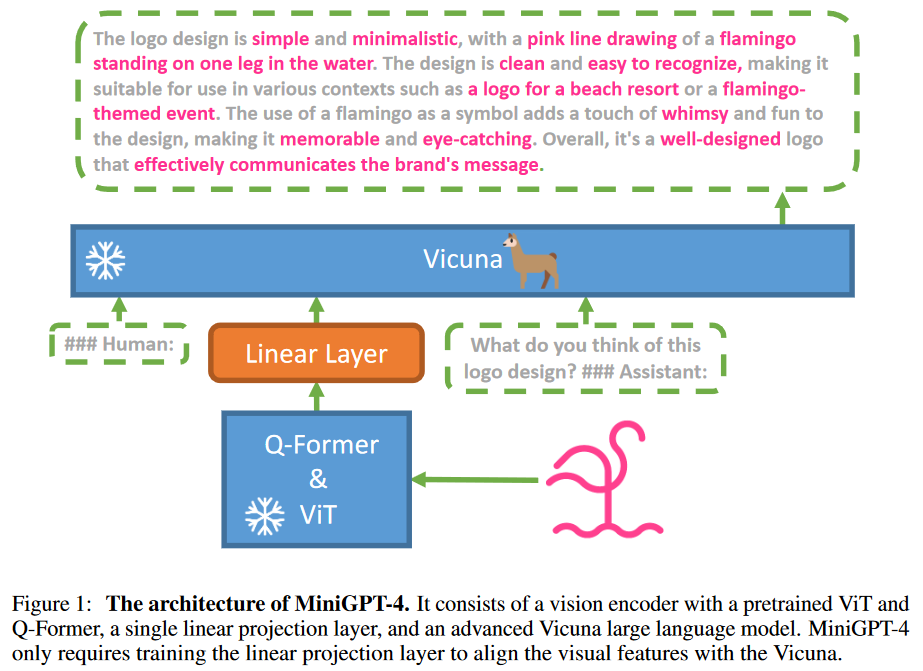
2. 第一阶段:预训练
预训练的目的是通过大量的image-text pairs来获取视觉-语言信息。其中通过linear层输出的特征会被当做soft prompt输入到LLM中,提示LLM生成相关文本。
问题:预训练的模型会生成重复单词或句子,碎片化的句子,不相关的内容,这些问题导致模型不能产生流畅的视觉对话
2. 第二阶段:微调
为了解决上述问题,作者收集了额外的high-quality image-text pairs来微调模型。但是在多模态方面,微调数据是很难获得的。作者使用第一阶段的数据来生成的对话,同时如果模型生成的token少于80,则增加“continue”的prompt令其生成更多,作者从Conceptual Caption数据集中随机挑选了5000个图片来生成描述,最后将得到的描述给ChatGPT进行优化,ChatGPT的prompt如下所示
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation.
最后,人工对每一个图片的描述进行检查,确保他是高质量的,手动refine这些描述并消除冗余单词或者句子,最终产生了3500个对话,用于第二阶段的对齐。
1.4 训练细节
数据集:LAION,conceptual Captions,SBU,大约5百万图文对
预训练:20K steps,bs=256,GPU=4-A100,大约10小时
微调:400,bs=12,GPU=1-A100,7分钟
1.5 模型依然存在的问题
幻觉:由于MiniGPT-4是基于LLM构建的,因此继承了LLM的幻觉问题
不全面的感知能力:MiniGPT-4的感知能力有限,他无法感知到图片中文本的细节信息,无法具有空间定位能力。有以下原因:1. 缺少空间位置信息和OCR标注的数据;2. 冻住的Q-Former可能会损失一些信息,例如visual-spatial grounding能力,可以通过使用一个更强的视觉感知模型来解决;3. 只训练一层投影层不能够提供充足的视觉文本的对齐能力。