c
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. Alibaba Group
1.1 论文动机
本文是在Qwen-LM的基础上进行改的,本文的Qwen-VL通过精心设计视觉编码器来使Qwen-LM能够处理图像信息,还有以下三个特征:输入输出交互,三阶段的训练,以及多语言的多模态预料训练。作者通过image-caption-box的tuple对实现grounding和text-reading能力,最终模型在相同尺寸的通用模型基础上在zero-shot和few-shot设置下达到了很好的效果。
下面是在benchmark上比较后的结果
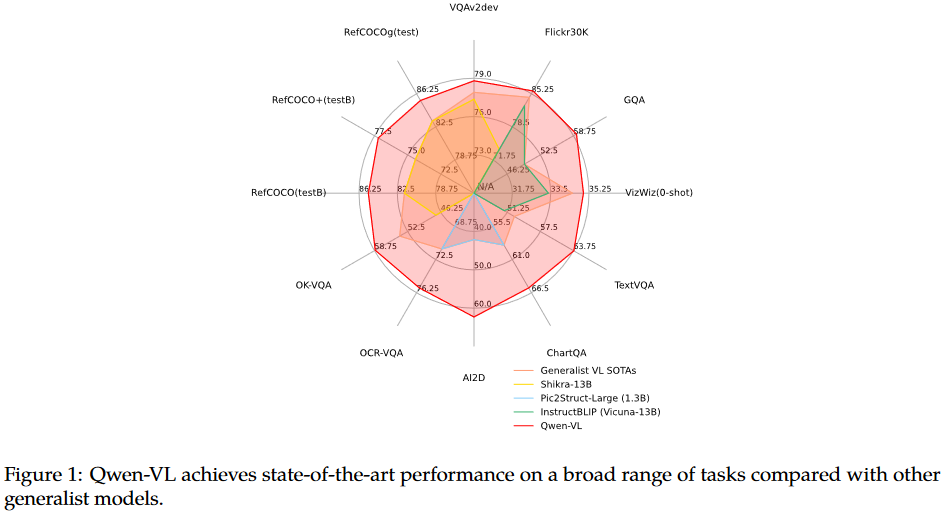
1.2 论文介绍
现有的large vision language models(LVLMs)经历了不充分的训练和优化,者最爱了进一步的探索和LVLMs的应用。现在的模型对细粒度的感知,例如object grounding和text reading能力有限。本文引入了一个新的visual receptor包含一个language-aligned visual encoder和一个position-aware adapter。整个模型通过三阶段来训练优化,本文的主要贡献如下
- 在相同的尺寸下,Qwen-VLs在各个benchmark上取得了较高的准确率,包含传统的benchmark以及dialogue benchmark。
- 多语种:Qwen-VLs在多语种的image-text pairs上进行训练,包含中英文等。
- 多图:在训练阶段,允许任意交织的image-text数据作为输入,也就是说可以在对话过程中加入多幅图进行理解。
- 细粒度的视觉理解:模型能够处理更高分辨率的图片,以及细粒度的语料,Qwen-VLs产生了更有竞争力的细粒度的视觉理解能力。
1.3 方法细节
1. 模型结构
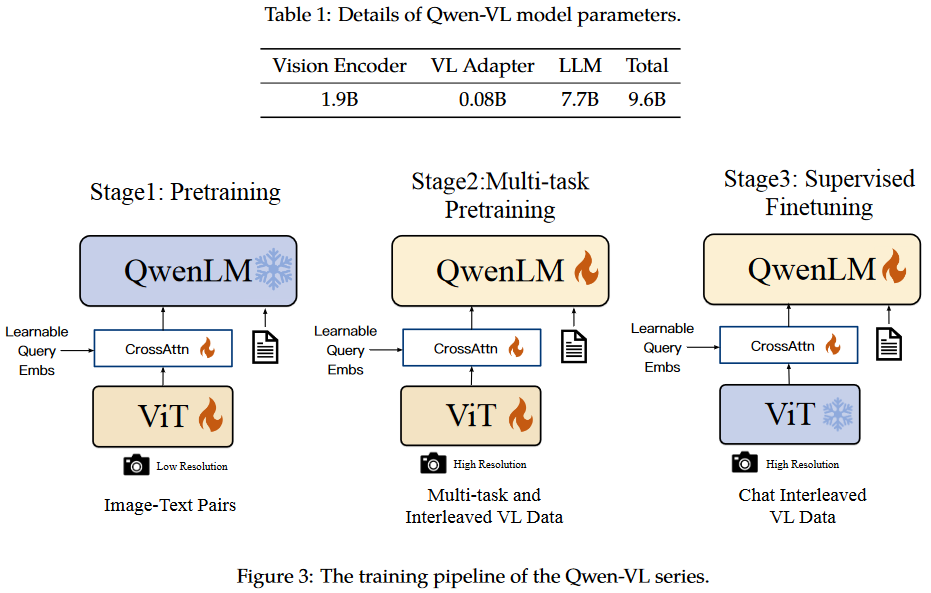
模型的整体架构如下图所示
- 大语言模型:模型由Qwen-7B初始化得到
- 视觉编码器:视觉编码器使用ViT结构,权重由Openclip的ViT-bigG初始化得到,在训练和测试阶段,图片首先被resize到特定的尺寸,vit的patch为14
- Position-aware Vision-Language Adapter:这个adapter主要用来压缩图像特征,包含一个single-layer的cross-attention模块,这个模块有256个可学习的query,用来压缩视觉特征到256(通过消融实验,256确实是最好的),这里使用的是2D absolute位置编码到QK上,减轻在压缩过程中可能产生的位置损失。最终输入到LLM中的只有256个Token。
2. 输入和输出
图像输入:为了区分图像和文本,对于图像加入了<img>Image</img>
Bounding box的输入和输出:对于任意的bounding box,归一化到[0, 1000),然后如下表示(,
), (
,
,这些字符被转化为text的形式,不需要额外的位置token,为了区分位置信息和文本信息,对于位置信息加入了
<box>Box</box>,为了匹配文本和相应的bounding box,对于描述的文本加入了<ref>Object</ref>.
1.4 训练细节
如之前所述,千问模型一共分为三阶段训练前两个阶段进行预训练,最后一个阶段进行微调
- (一)第一阶段预训练
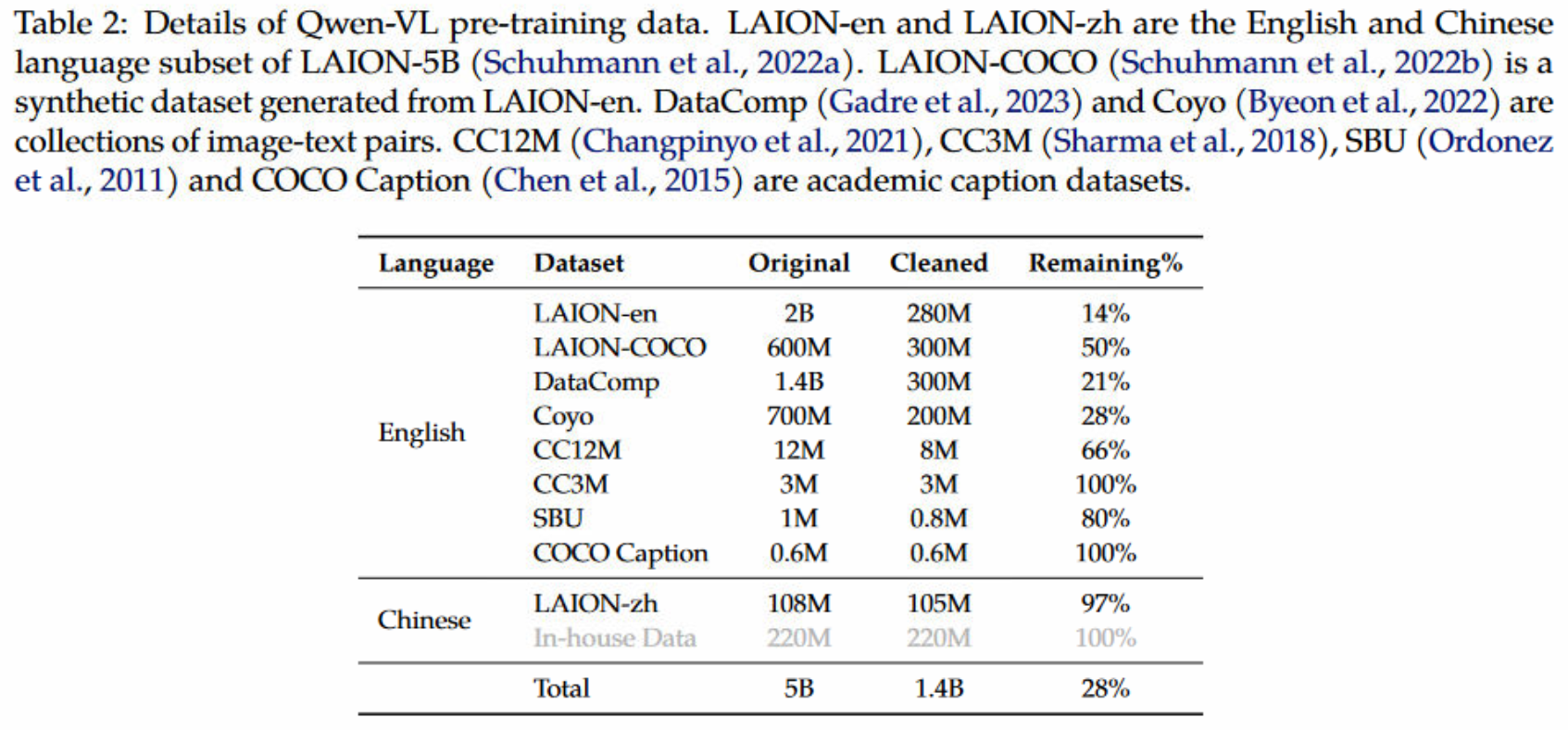
使用大规模的,弱监督的,网络中爬取的image-text pairs,预训练数据包含几个公开的可获得的资源以及一些in-house数据,数据集的形式如下所示,其中,有5B的image-text pairs,cleaning之后,只有1.4B数据,其中77.3%的英文数据和22.7%的中文数据。第一阶段冻结LLM,优化ViT和adapter,输入图片被resize为。
训练细节:lr=2e-4,bs=30720,step=50k
- (二)第二阶段预训练
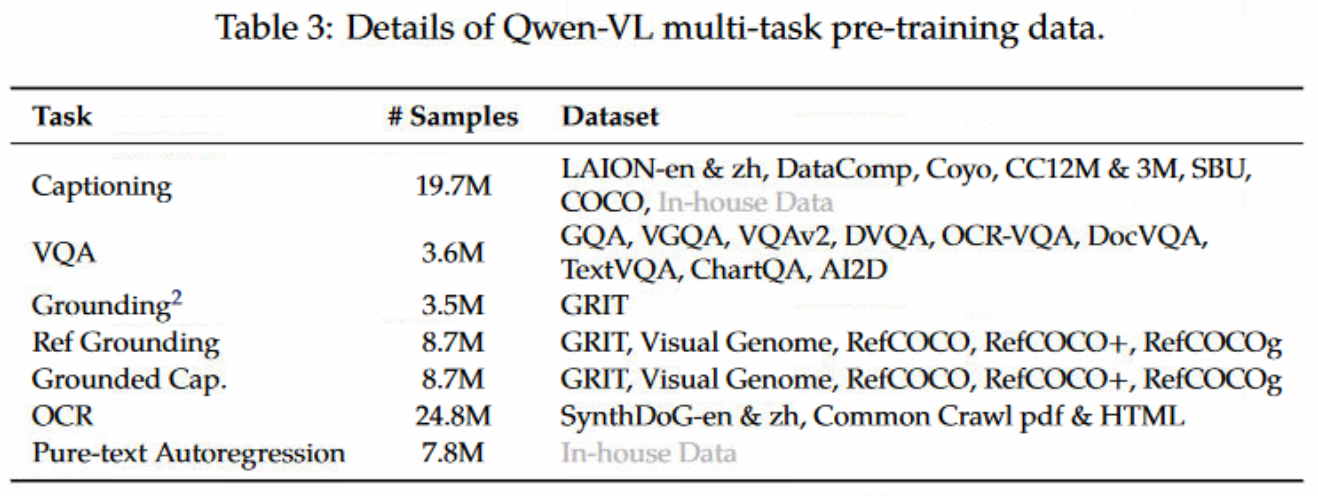
第二阶段预训练为多任务预训练,用高质量的更细粒度的视觉语言标记数据,同时使用更大的输入分辨率,以及交织的图文对。如下所示,作者使用了7个任务的数据集。
- (三)第三阶段微调
作者用Qwen-VL进行指令微调,提升指令微调能力和对话能力,训练处interactive Qwen-VL-Chat模型。通常多模态模型只能进行单个图像的对话和推理,而且仅限于图像内容的理解。作者通过手动注释和模型生成等方法生成了额外的数据,将定位和多图像理解纳入了Qwen-VL模型中,此外还加入了多模态和纯文本对话数据,确保模型在对话能力的通用性,数据总共为350K,此阶段冻结视觉编码器,优化LLM和adapter。